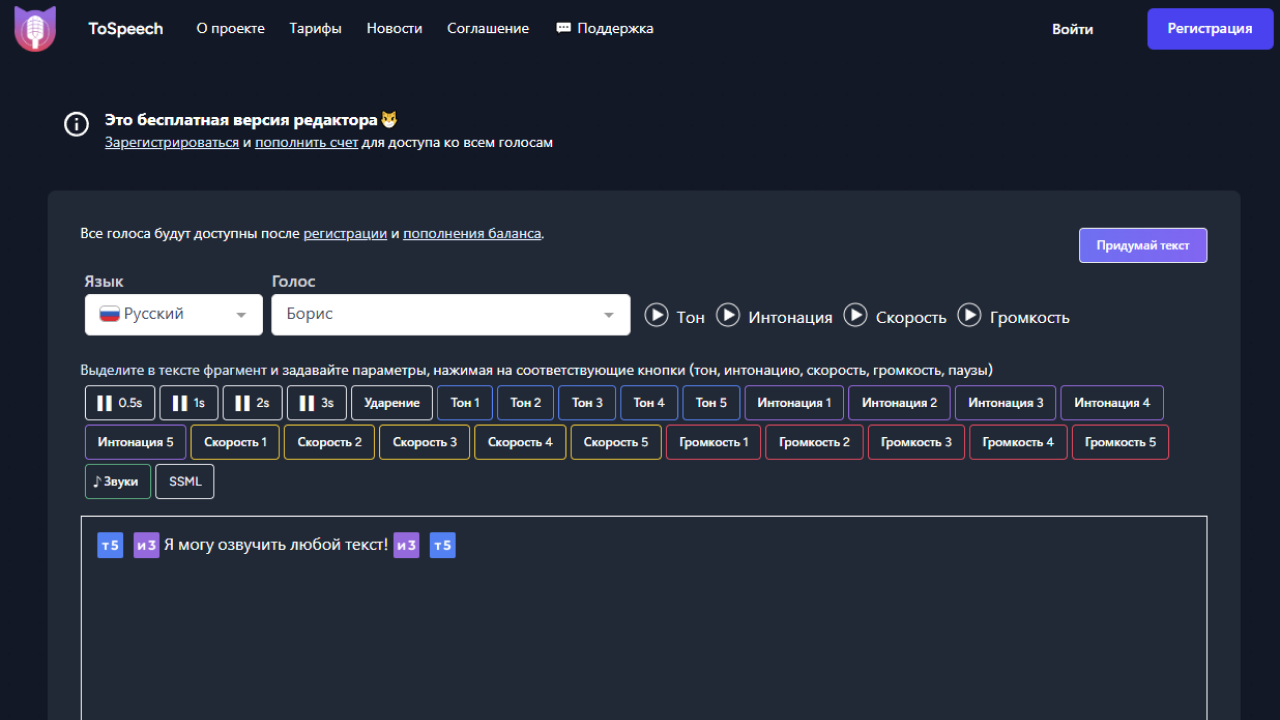
TOSPEECH — это веб-сервис для преобразования текста в естественно звучащую речь с использованием современных нейросетевых технологий.
Проект создавался как практическое решение задачи быстрого и качественного озвучивания контента без участия дикторов и студий записи.
Основная цель — создать инструмент, который позволяет:
- за несколько минут получать профессиональную аудиодорожку
- гибко управлять звучанием
- контролировать интонацию, эмоции, темп и стиль речи
💡 Идея и предпосылки создания
Идея проекта появилась из реальной потребности ускорить создание голосового контента.
Большинство существующих решений:
- дают стандартный синтез речи
- не позволяют управлять подачей текста
➡️ Это ограничивает использование в коммерческих задачах, где важна эмоциональная составляющая.
Цель:
Создать сервис, в котором пользователь управляет голосом так же, как режиссёр управляет диктором в студии.
🎯 Задачи проекта
Перед разработкой были поставлены ключевые задачи:
- обеспечить максимально естественное звучание речи
- реализовать удобный интерфейс генерации
- дать пользователю контроль над параметрами звучания
- создать масштабируемую архитектуру
- предусмотреть интеграцию через API
⚙️ Реализованный функционал
В результате был разработан полноценный SaaS-сервис синтеза речи.
🔊 Генерация речи
Пользователь может:
- преобразовывать текст в аудио
- использовать нейросетевые голоса
- управлять параметрами звучания
Настройки включают:
- интонацию
- скорость
- громкость
- стиль произношения
🎭 Эмоциональные режимы
Ключевая особенность сервиса — управление эмоциями:
- шёпот
- грусть
- раздражение
- радость
➡️ Это позволяет использовать сервис для:
- сторителлинга
- диалогов
- коммерческой озвучки
🗣️ Диалоги между голосами
Реализована возможность создания диалогов:
- несколько голосов
- разные языки
- индивидуальная эмоциональная окраска
➡️ Позволяет генерировать:
- разговорные сцены
- обучающие материалы
- презентации
- видеоконтент
🌍 Мультиязычность
Сервис поддерживает:
- озвучку на разных языках
- комбинирование языков в одном проекте
➡️ Используется для:
- локализации продуктов
- выхода на международные рынки
⚡ Асинхронная генерация
- обработка происходит через очередь задач
- стабильная работа при высокой нагрузке
- поддержка длинных текстов
🏗️ Техническая реализация
Проект реализован как масштабируемое веб-приложение.
Архитектура:
- разделение API и сервиса обработки
- очередь задач для генерации аудио
- горизонтальное масштабирование
Дополнительно:
- система авторизации
- управление пользовательскими проектами
- хранение аудиофайлов
💼 Практические кейсы использования
🎬 Контент-создатели
- озвучка видео
- создание обучающих материалов
➡️ Сокращение времени производства:
с дней → до нескольких часов
🎓 Образование
- автоматическая генерация уроков
- масштабирование курсов на разные языки
🏢 Бизнес
- голосовые уведомления
- инструкции
- внутреннее обучение
- автоматизированные сценарии
🌐 Локализация
- быстрая озвучка на разных языках
- выход на новые рынки без дикторов
📈 Результаты проекта
В результате был создан полноценный AI-сервис, который:
- автоматизирует создание голосового контента
- снижает зависимость от ручного производства
- ускоряет выпуск контента
Пользователи получают:
- быструю генерацию озвучки
- профессиональное качество
- гибкое управление голосом
- возможность интеграции в свои продукты
🧠 Итог
TOSPEECH демонстрирует практическое применение нейросетевых технологий в бизнесе.
Проект показывает, как AI позволяет:
- заменить сложные этапы производства
- снизить затраты
- ускорить процессы
- сохранить высокое качество
💡 Ключевой вывод
Современные AI-решения позволяют:
- автоматизировать создание аудиоконтента
- масштабировать его без дополнительных ресурсов
- создавать гибкие и управляемые голосовые сценарии
Нужен похожий проект?
Подскажем архитектуру, оценим сроки и предложим путь к запуску.
Обсудить задачу →